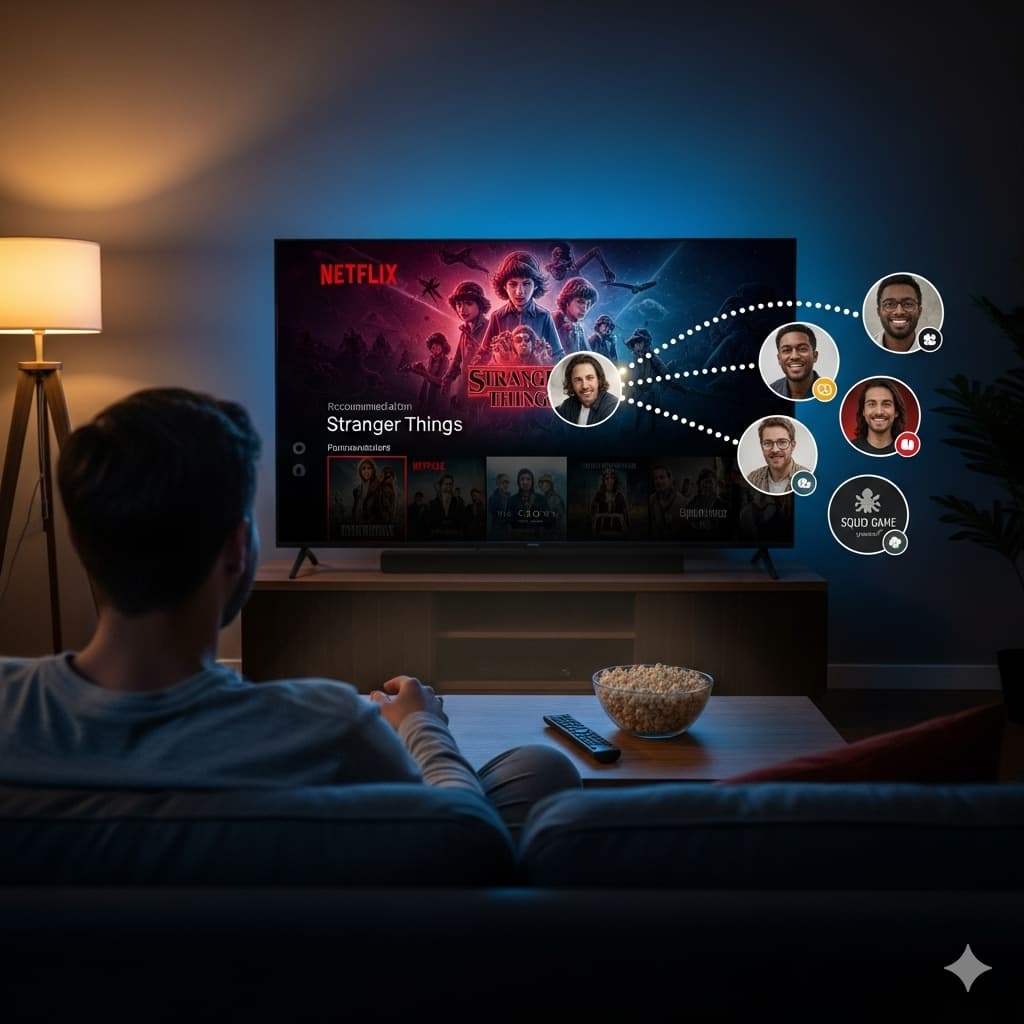
¿Alguna vez te has preguntado cómo Netflix o Spotify saben exactamente qué recomendarte? La respuesta podría ser el algoritmo K-Nearest Neighbors (KNN), una joya del aprendizaje automático supervisado. A pesar de su nombre técnico, su lógica es tan simple como la de un buen vecino.
¿Qué es KNN?
El algoritmo KNN se basa en una idea muy intuitiva:
“Un objeto se parece a sus vecinos más cercanos”.
Esto significa que, para clasificar un nuevo dato, el algoritmo busca los k ejemplos más cercanos en el conjunto de entrenamiento y decide la etiqueta en función de ellos (por ejemplo, por mayoría en clasificación).
Ejemplo gráfico sencillo
Imagina que tienes un gráfico con puntos rojos (clase A) y azules (clase B).
Si aparece un nuevo punto verde y sus 3 vecinos más cercanos son rojos, entonces el punto será clasificado como rojo (clase A).
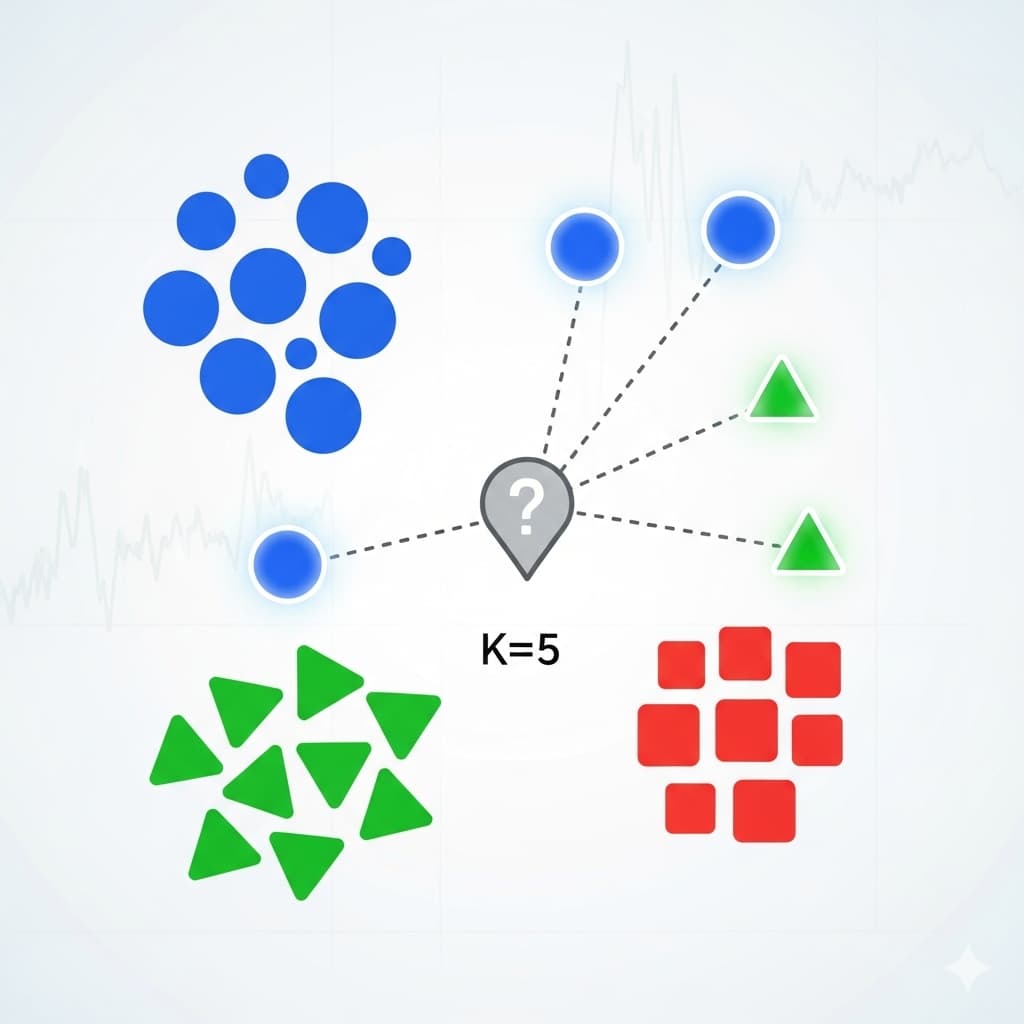
Cómo funciona el algoritmo KNN
- Se elige un valor de k (el número de vecinos a considerar).
- Se calcula la distancia entre el punto a clasificar y todos los puntos de entrenamiento (distancia euclidiana, Manhattan, etc.).
- Se seleccionan los k vecinos más cercanos.
- En clasificación: se asigna la clase más frecuente entre esos vecinos.
- En regresión: se toma el promedio del valor de esos vecinos.
Ventajas de KNN
- Simplicidad: fácil de entender e implementar.
- No requiere entrenamiento complejo.
- Funciona bien en datasets pequeños y medianos.
Desventajas de KNN
- Computacionalmente costoso en datasets grandes (hay que calcular distancias con todos los puntos).
- Sensible a valores atípicos y ruido en los datos.
- Depende de la elección adecuada de k y la métrica de distancia.
Implementación en Python
Un ejemplo de uso práctico con clasificación de iris dataset:
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # Cargar dataset iris = load_iris() X, y = iris.data, iris.target # Dividir en entrenamiento y prueba X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Crear modelo KNN con k=3 knn = KNeighborsClassifier(n_neighbors=3) knn.fit(X_train, y_train) # Evaluación accuracy = knn.score(X_test, y_test) print("Precisión del modelo:", accuracy)
Aplicaciones reales de KNN
- Reconocimiento de patrones: escritura a mano, imágenes, rostros.
- Sistemas de recomendación: películas, productos.
- Medicina: clasificación de tumores como benignos o malignos.
- Finanzas: detección de fraudes y segmentación de clientes.
Conclusión
El algoritmo KNN demuestra que no siempre se necesita un modelo complejo para obtener buenos resultados. Gracias a su sencillez y versatilidad, sigue siendo una herramienta clave para aprender y aplicar machine learning en casos prácticos.