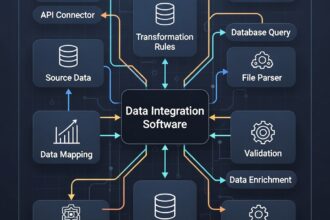
Cómo funciona el algoritmo de compresión: El arte de reducir datos sin perder el alma
¿Alguna vez te has preguntado cómo es posible que una película de alta calidad de varios gigabytes se comprima en un archivo más pequeño que puedes descargar en cuestión de minutos? ¿O cómo las fotos que tomas con tu teléfono se almacenan sin ocupar todo el espacio disponible? La respuesta está en un pilar fundamental de la informática: los algoritmos de compresión.
¿Qué es la compresión de datos?
En esencia, la compresión de datos es el proceso de codificar la información utilizando menos bits de los que se usarían en su forma original. El objetivo es reducir el tamaño de un archivopara ahorrar espacio de almacenamiento y acelerar las transferencias a través de redes. Piensa en ello como si estuvieras empacando una maleta para un viaje: en lugar de meter la ropa al azar, la doblas o enrollas para que quepa más en el mismo espacio.

Hay dos tipos principales de compresión:
- Compresión sin pérdida (lossless): Este método reduce el tamaño del archivo sin sacrificar ni un solo bit de información. El archivo descomprimido es una copia exacta del original. Es el método ideal para datos que no pueden permitirse ninguna pérdida, como archivos de texto, documentos de código o bases de datos. Un ejemplo común es el formato ZIP.
- Compresión con pérdida (lossy): Como su nombre indica, este tipo de compresión descarta cierta cantidad de información para lograr una reducción de tamaño mucho más significativa. Aunque el archivo descomprimido no es idéntico al original, la pérdida es imperceptible para el ojo humano o el oído en la mayoría de los casos. Este método se usa comúnmente en archivos multimedia, como imágenes (JPEG), audio (MP3) y video (MPEG-4).
El cerebro detrás de la magia: Algoritmos clave
Para entender cómo funciona la compresión, veamos dos de los algoritmos más influyentes:
1. Huffman Coding (sin pérdida)
Este algoritmo, creado por David A. Huffman, es una técnica de compresión sin pérdida que se basa en la frecuencia de los caracteres. La idea es simple pero brillante: a los caracteres que aparecen con más frecuencia se les asigna una representación más corta (un código de menos bits), mientras que a los que aparecen con menos frecuencia se les asigna una representación más larga. Por ejemplo, en un texto en español, la letra ‘e’ podría tener un código de 3 bits, mientras que la ‘x’ podría tener un código de 8 bits. Al final, el tamaño total del archivo se reduce porque las letras más comunes ocupan menos espacio.
2. Discrete Cosine Transform (DCT) (con pérdida)
El DCT es el corazón de muchos formatos de compresión con pérdida, como el JPEG para imágenes. Funciona transformando los datos de una imagen (o sonido) en coeficientes de frecuencia. Los detalles de alta frecuencia (como el ruido fino o los colores ligeramente variados) que son menos perceptibles para el ojo humano se descartan o se cuantifican con menos precisión, mientras que los detalles de baja frecuencia (que definen las formas y colores principales) se mantienen. Este proceso es lo que permite una reducción tan drástica del tamaño del archivo.
El futuro de la compresión
Con la explosión de datos en la era digital, la compresión sigue siendo una herramienta vital. Los avances en algoritmos de aprendizaje automático están abriendo nuevas fronteras, permitiendo una compresión más eficiente y adaptativa. Desde la transmisión de video 4K en tiempo real hasta la optimización del almacenamiento en la nube, los algoritmos de compresión son los héroes anónimos que hacen que nuestro mundo digital sea más rápido y manejable.